출처 : http://tuckoo.tistory.com/446
수십개의 gif 파일을 다루는 일을 하다가 신기한 점을 발견했다.
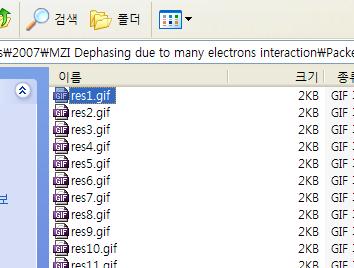
바로 파일명이 'res9' 다음에 'res10'이 오도록 정렬되어 있다는것!!
파일명을 정렬할 때 단순히 문자열로 비교한다면 'res1' 다음에는 'res10'이 와야한다. 'cast', 'cat' 그리고 'castle' 이 세 단어가 사전에는 'cast' - 'castle' - 'cat' 순서로 실려 있듯이. 그런데 저런 식으로 정렬이 되었다는 것은 파일명 정렬 알고리즘이 'res' 뒤에 붙은 숫자를 문자열이 아닌 숫자로 인식한다고 볼 수 있다.
정확히 어떤 기준일지 궁금해서 약간 실험을 해봤다.

'-'는 컴퓨터에서는 사전순으로 정렬할 때 숫자보다 앞에 있는 것으로 취급된다 (아스키 코드값이 숫자보다 작다). 이 결과를 분석해 보면
어떤 방법으로 비교하면 이렇게 비교를 할 수 있을까. 문자열의 영역을 나누어 비교하면 이런 식으로 작동하게 만들 수 있을 것 같다. 예를 들면 '-3' 같은 경우에는 [문자열] [숫자] 로 영역을 나누는 것이다. 서로 다른 문자열들끼리 비교할 때에는 앞에서부터 영역별로 비교해나간다. 이 방법이라면 정렬 결과를 잘 설명할 수 있고 구현도 그리 복잡하지 않으므로 파일명 비교하는 부분은 이렇게 짜여졌으리라 예상할 수 있다.
그러면 '--'와 '56', '--a'는 어떻게 된것일까? 아마 [문자열] 영역을 [특수 문자열]과 [영문자]로 나누었을 것이다. 영역 간의 우선순위도 정해져야 하는데 아스키 코드상의 배열로 볼 때 [특수 문자열] - [숫자] - [영문자] 순서일 공산이 크다. '--'는 [특수문자열], '56'은 [숫자], 그리고 '--a' 는 [특수문자열] [영문자] 이므로 위와 같이 정렬되는 것이 맞다.
이 가설은 다음과 같은 실험(?)으로 검증할 수 있다.

'{'과 '}'은 아스키 코드 상으로는 'a' 보다 뒤에 있는 문자이지만 xp 파일명 정렬방식에서는 '--a' 보다 앞에 온다!
구글에서 검색을 해보니 windows xp에는 StrCmpLogicalW라고 하는 새로운 문자열 비교 API가 추가되었다고 한다. 초기에는 숫자가 아주 클 때에 문제가 생겼다는 이야기도 있는데 충분히 있을법한 버그이다. [숫자] 부분에는 정수만 들어오니까 마음 편히 int 로 변수를 선언하고 크기 비교를 하지 않았다면 오버플로우가 났겠지.

델파이에서 사용법
함수 원형으로 XP에서는 'shlwapi.dll' 에 구현되어 있음.
int StrCmpLogicalW(
LPCWSTR psz1,
LPCWSTR psz2
);
수십개의 gif 파일을 다루는 일을 하다가 신기한 점을 발견했다.
바로 파일명이 'res9' 다음에 'res10'이 오도록 정렬되어 있다는것!!
파일명을 정렬할 때 단순히 문자열로 비교한다면 'res1' 다음에는 'res10'이 와야한다. 'cast', 'cat' 그리고 'castle' 이 세 단어가 사전에는 'cast' - 'castle' - 'cat' 순서로 실려 있듯이. 그런데 저런 식으로 정렬이 되었다는 것은 파일명 정렬 알고리즘이 'res' 뒤에 붙은 숫자를 문자열이 아닌 숫자로 인식한다고 볼 수 있다.
정확히 어떤 기준일지 궁금해서 약간 실험을 해봤다.
'-'는 컴퓨터에서는 사전순으로 정렬할 때 숫자보다 앞에 있는 것으로 취급된다 (아스키 코드값이 숫자보다 작다). 이 결과를 분석해 보면
- '--21'을 '-' 와 -21로 해석하지 않았다. 즉, 음수는 처리하지 않는다.
- '-11'이 '--21'보다 앞에 있는 것으로 미루어 볼 때 숫자를 제외한 나머지 문자열을 기준으로 비교를 하는 것을 알 수 있다. 숫자를 제외하고 나면 '-11'은 '-'이 되고 '--21'은 '--'가 되므로 '-'이 '--'보다 앞에 온다.
- '--'와 '--21'의 순서로 볼 때 숫자가 있는 것이 숫자가 없는것보다 앞에 온다.
어떤 방법으로 비교하면 이렇게 비교를 할 수 있을까. 문자열의 영역을 나누어 비교하면 이런 식으로 작동하게 만들 수 있을 것 같다. 예를 들면 '-3' 같은 경우에는 [문자열] [숫자] 로 영역을 나누는 것이다. 서로 다른 문자열들끼리 비교할 때에는 앞에서부터 영역별로 비교해나간다. 이 방법이라면 정렬 결과를 잘 설명할 수 있고 구현도 그리 복잡하지 않으므로 파일명 비교하는 부분은 이렇게 짜여졌으리라 예상할 수 있다.
그러면 '--'와 '56', '--a'는 어떻게 된것일까? 아마 [문자열] 영역을 [특수 문자열]과 [영문자]로 나누었을 것이다. 영역 간의 우선순위도 정해져야 하는데 아스키 코드상의 배열로 볼 때 [특수 문자열] - [숫자] - [영문자] 순서일 공산이 크다. '--'는 [특수문자열], '56'은 [숫자], 그리고 '--a' 는 [특수문자열] [영문자] 이므로 위와 같이 정렬되는 것이 맞다.
이 가설은 다음과 같은 실험(?)으로 검증할 수 있다.
'{'과 '}'은 아스키 코드 상으로는 'a' 보다 뒤에 있는 문자이지만 xp 파일명 정렬방식에서는 '--a' 보다 앞에 온다!
구글에서 검색을 해보니 windows xp에는 StrCmpLogicalW라고 하는 새로운 문자열 비교 API가 추가되었다고 한다. 초기에는 숫자가 아주 클 때에 문제가 생겼다는 이야기도 있는데 충분히 있을법한 버그이다. [숫자] 부분에는 정수만 들어오니까 마음 편히 int 로 변수를 선언하고 크기 비교를 하지 않았다면 오버플로우가 났겠지.
델파이에서 사용법
함수 원형으로 XP에서는 'shlwapi.dll' 에 구현되어 있음.
int StrCmpLogicalW(
LPCWSTR psz1,
LPCWSTR psz2
);
interface
function StrCmpLogicalW(psz1, psz2: PWideChar): integer; stdcall;
function CompareFileName(p1 : string; p2 : string) : integer; overload;
function CompareFileName(AList : TStringList; idx1, idx2 : integer) : integer; overload;
implementation
function StrCmpLogicalW; external 'shlwapi.dll' name 'StrCmpLogicalW';
//Because it compares unicode strings, I'm not sure how to call it when I want to compare ansi strings.
//It seems to be enough to cast strings to WideString and then to PWideChar, however, I have no idea whether
//this approach is correct:
function CompareFileName(p1 : string; p2 : string) : integer;
begin
result := StrCmpLogicalW( PWideChar(WideString(p1)),
PWideChar(WideString(p2)) );
end;
function CompareFileName(AList : TStringList; idx1, idx2 : integer) : integer;
begin
result := StrCmpLogicalW( PWideChar(WideString(AList[idx1])),
PWideChar(WideString(AList[idx2])) );
end;
// 사용예제
procedure LoadMultiFiles;
begin
TStringList(OpenDialog1.Files).CustomSort(CompareFileName);
sl.Text := TStringList(OpenDialog1.Files).Text;
end;
C로 구현된 소스 void SortFileName(CStringArray& arrStr)
{
qsort(arrStr.GetData(), arrStr.GetSize(), sizeof(CString*), CompareFileName);
}
int CompareFileName(const void* p1, const void* p2)
{
TCHAR *sz1 = ((CString*)(p1))->GetBuffer(0);
TCHAR *sz2 = ((CString*)(p2))->GetBuffer(0);
int nPos1 = -1;
int nPos2 = -1;
int nEndPos1;
int nEndPos2;
int nResult;
while (1)
{
nPos1++;
nPos2++;
// Make sure we haven't hit the end of either of the strings
if (sz1[nPos1] == 0 && sz2[nPos2] == 0)
return 0;
if (sz1[nPos1] == 0)
return -1;
if (sz2[nPos2] == 0)
return 1;
// See if this part of both strings is a number
if (sz1[nPos1] >= _T('0') && sz1[nPos1] <= _T('9') &&
sz2[nPos2] >= _T('0') && sz2[nPos2] <= _T('9'))
{
// Find the end of each number
nEndPos1 = nPos1;
do
{
nEndPos1++;
} while (sz1[nEndPos1] >= _T('0') && sz1[nEndPos1] <= _T('9'));
nEndPos2 = nPos2;
do
{
nEndPos2++;
} while (sz2[nEndPos2] >= _T('0') && sz2[nEndPos2] <= _T('9'));
while (true)
{
if (nEndPos1 - nPos1 == nEndPos2 - nPos2)
{
// Both numbers are the same length, just compare them
nResult = _tcsnicmp(sz1 + nPos1, sz2 + nPos2, nEndPos1 - nPos1);
if (nResult == 0)
{
nPos1 = nEndPos1 - 1;
nPos2 = nEndPos2 - 1;
break;
}
else
{
return nResult;
}
}
else if (nEndPos1 - nPos1 > nEndPos2 - nPos2)
{
// First number is longer, so if it's not zero padded, it's bigger
if (sz1[nPos1] == _T('0'))
nPos1 ++;
else
return 1;
}
else
{
// Second number is longer, so if it's not zero padded, it's bigger
if (sz2[nPos2] == _T('0'))
nPos2 ++;
else
return -1;
}
}
}
else
{
// One or both characters is not a number, so just compare them as a string
nResult = _tcsnicmp(sz1 + nPos1, sz2 + nPos2, 1);
if (nResult != 0)
{
return nResult;
}
}
}
}
'프로그래밍' 카테고리의 다른 글
| GIMP를 이용한 다계층 아이콘 만들기 (1) | 2010.12.20 |
|---|---|
| MySQL DUMP SQL문을 MSSQL에서 실행하기 위한 TEXT변환 (1) | 2010.09.08 |
| 울트라에디트(UltraEdit)에서 특수문자 바꾸기 (3) | 2010.08.20 |
| PDF문서의 MediaBox, CropBox, ArtBox에 대하여 (3) | 2010.01.20 |
| UML 다이어그램 예제 (0) | 2009.05.15 |
